Handling text with string methods#
This document deals with handling text, a generally challenging task in data anaylses. We will cover general str methods and introduce regular expressions (regex) to identify patterns in strings.
Why is handling text important?#
We will illustrate with several examples.
Predicting stock returns
|
|---|
Truncated table of positive and negative text for predicting stock returns [Glasserman et al., 2020] |

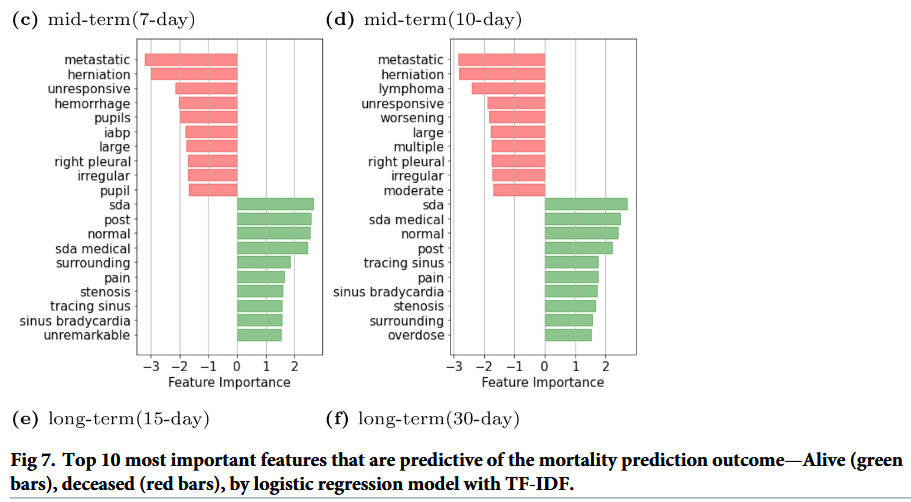
Parsing clinical notes
|
|---|
Text importance in long-term mortality prediction, truncated from table in [Mahbub et al., 2022] |
Untangling inspection violations
import pandas as pd
food = pd.read_csv('../data/inspections.csv')
violations = food['Violations']
violations[~violations.isna()].head()
violations[0]
Why is handling text difficult?#

https://padlet.com/yuchan2021/what-makes-handling-text-data-difficult-t6k3ssnc6q7x7td3
Two primary goals of handling text#
Canonicalization : transforming text of different representations into a standard form.
|
|---|
Example of canonization for joining tables with mismatched labels (DS 100). |
Extraction: extracting information into useful features.
Example: extracting dates, times, and other information from log files:
169.237.46.168 - - [26/Jan/2024:10:47:58 -0800] "GET /cs150/Winter24/ HTTP/1.1" 200 2585 "http://cs.northwestern.edu/courses"
day, month, year = "26", "Jan", "2024"
hour, minute, seconds = "10", "47", "58"
Python string methods and pandas str#
In base Python, manipulating strings is possible through various string methods.
s = "ABc,123,$%^&"
s
'ABc,123,$%^&'
s.lower()
'abc,123,$%^&'
s.upper()
'ABC,123,$%^&'
s.replace(',', ' ')
'ABC 123 $%^&'
s.split(',')
['ABC', '123', '$%^&']
'ABD' in s
False
len(s)
12
s[7:9]
',$'
Issue?
Although the string operations are useful (recall our apply() function), Python assumes we work with one string at a time.
Looping over each entry of a large dataset becomes slow.
In pandas, most of the operations are vectorized to perform on multiple entries simultaneously.
Operation |
Python (single string) |
|
|---|---|---|
transformation |
|
|
replacement/deletion |
|
|
split |
|
|
substring |
|
|
membership |
|
|
length |
|
|
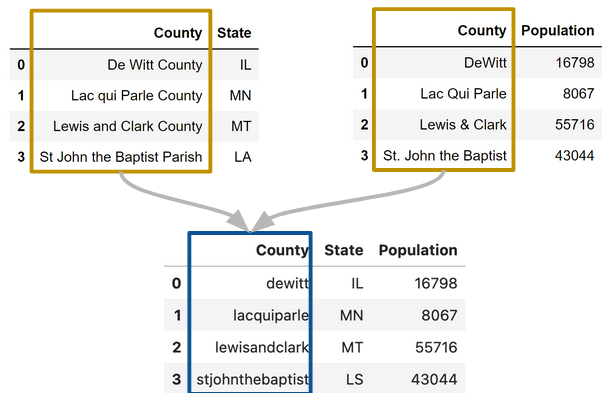
Practice: canonicalization#
Combine the following two tables into one, showing the county, state, and population as columns.
import io
import pandas as pd
county_population = pd.read_csv(
io.StringIO('''County,Population
DeWitt,16798
Lac Qui Parle,8067
Lewis & Clark,55716
St. John the Baptist,43044'''))
county_state = pd.read_csv(
io.StringIO('''County,State
De Witt County,IL
Lac qui Parle County,MN
Lewis and Clark County,MT
St John the Baptist Parish,LS'''))
def canon_text(s):
result = (s.str.lower()
.str.replace('&', 'and')
.str.replace(' ', '')
.str.replace('county', '')
.str.replace('parish', '')
.str.replace('.', '')
)
return result
canon_text(county_population['County'])
canon_text(county_state['County'])
0 dewitt
1 lacquiparle
2 lewisandclark
3 stjohnthebaptist
Name: County, dtype: object
Regular expressions#
Many text data have “some” inherited structure, e.g., log files, concatenated violation codes.
Practice: manipulating logs#
Starting with an example:
Consider the two log entries below, how can we extract the dates and times, perhaps with split()?
169.237.46.168 - - [26/Jan/2024:10:47:58 -0800] "GET /cs150/Winter24/150.html HTTP/1.1" 200 2585 "http://cs.northwestern.edu/courses/"
193.205.203.3 - - [2/Feb/2023:17:23:6 -0800] "GET /iems394/Notes/dim.html HTTP/1.0" 404 302 "http://iems.northwestern.edu/academics/"
line1 = '169.237.46.168 - - [26/Jan/2024:10:47:58 -0800] "GET /cs150/Winter24/150.html HTTP/1.1" 200 2585 "http://cs.northwestern.edu/courses/"'
line2 = '193.205.203.3 - - [2/Feb/2023:17:23:6 -0800] "GET /iems394/Notes/dim.html HTTP/1.0" 404 302 "http://iems.northwestern.edu/academics/"'
def return_date_time(line):
result = line.split('[')[1].split(']')[0]
return result
return_date_time(line1)
'26/Jan/2024:10:47:58 -0800'
return_date_time(line2)
'2/Feb/2023:17:23:6 -0800'
Regular expression is an alternative way to perform systematic pattern recognition.
Implemented in Python
relibrary and also inpandasstrmethods.
Back to the log lines…
import re
pattern = r'\[(\d+)\/(\w+)\/(\d+):(\d+):(\d+):(\d+) (.+)\]' # pattern to find in text
match = re.findall(pattern, line1)[0] # try to match line to string
match
day, month, year, hour, minute, second, time_zone = match
Basic regex#
A regex is a sequence of characters that specifies a search pattern.
Log file example (characters separated for legibility, the following pattern no longer matches):
\[ (\d+) \/ (\w+) \/ (\d+) : (\d+) : (\d+) : (\d+) (.+) \]
corresponds to
[ (numbers) / (alphanumerics) / (numbers) : (numbers) : (numbers) : (numbers) (anything else) ]
Social Security Number example:
[0-9]{3}-[0-9]{2}-[0-9]{4}
corresponds to
3digits dash 2digits dash 4digits.
There is no way (and no reason) to memorize regex!
On a high level,
Understand what regex can do.
Parse and create regex patterns, using reference.
Toward more details,
Build up vocabulary (metacharacter, escape character, group, …) to help describe regex patterns.
Understand the difference between
(),[],{}.Design patterns using
\d,\s,\w,[...-...], etc.Use Python and
pandasmethods.
Learning regex with regex101.com#
Sample text:
0.70 - Coffee
0.75 - Cake slice
19.99 - Video game
12 - Lunch
6.99 - Spotify monthly charge
22.24 - Travel mug
7 - Cinema ticket
15 - Lunch
Total: 85.62
Basic operations:#
Concatenation, i.e. consecutive characters
|, or operator*, zero or more+, one or more(), consider as a group
Note: |, *, +, () are metacharacters. They represent operations, not the literal character.
Operation |
Order |
Example |
Matches |
Doesn’t match |
|---|---|---|---|---|
concatenation(consecutive chars) |
3 |
AABAAB |
AABAAB |
every other string |
or, | |
4 |
AA|BAAB |
AA BAAB |
every other string |
* (zero or more) |
2 |
AB*A |
AA ABBBBBBA |
AB ABABA |
group (parenthesis) |
1 |
A(A|B)AAB |
AAAAB ABAAB |
every other string |
(AB)*A |
A ABABABABA |
AA ABBA |
More operations:#
., matches any character[], define a character class?, zero or one{x}, repeat exactly x times{x, y}, repeat between x and y times
Character classes:#
[A-Z], any uppercase letter between A and Z[0-9], any digit between 0 and 9[A-Za-z0-9], any letter, any digit
Built-in classes:
\wmeans “word-like”, equivalent to[A-Za-z0-9]\dmeans “digit”, equivalent to[0-9]\smeans “space”, matches whitespace
Negation of class:
Use ^ to negate a class, meaning match any character but the ones in the class.
\W,\D,\Sare the negations of each of the built-in classes
Operation |
Example |
Matches |
Doesn’t match |
Doesn’t match |
|---|---|---|---|---|
any character(except newline) |
.U.U.U. |
CUMULUS JUGULUM |
SUCCUBUS TUMULTUOUS |
every other string |
character class |
[A-Za-z][a-z]* |
word Capitalized |
camelCase 4illegal |
every other string |
repeated exactly a times: {a} |
j[aeiou]{3}hn |
jaoehn jooohn |
jhn jaeiouhn |
AB ABABA |
repeated from a to b times: {a,b} |
j[ou]{1,2}hn |
john juohn |
jhn jooohn |
every other string |
at least one |
jo+hn |
john joooooohn |
jhn jjohn |
AA ABBA |
Practice: RegEx receipt#
Develop a regex pattern for all items in the receipt (excluding the total):
0.70 - Coffee
0.75 - Cake slice
19.99 - Video game
12 - Lunch
6.99 - Spotify monthly charge
22.24 - Travel mug
7 - Cinema ticket
15 - Lunch
Total: 85.62
More examples#
Date: 26/Jan/2024
\d{1,2}\/[A-Z][a-z]{2}\/[0-9]{4}
Academic email address:
(\w+)((\.|\-)?(\w+)?)*@\S+\.edu
Course number:
(\w+)\s*\d{3}
Zip-code:
^[0-9]{5}(\-[0-9]{4})?$
Examples of regex with Python and pandas#
Python#
import re
text = "<div><td valign='top'>Moo</td></div>"
pattern = r"(<[^>]+>)" # r"..." indicates a raw string
What does this pattern match?
re.match(pattern, text)[0]
Reminder: If we were to work with many strings (say in a dataset) at once, Python would loop through each one.
pandas#
import pandas as pd
texts = ["<div><td valign='top'>Moo</td></div>",
"<a href='http://ds100.org'>Link</a>",
"<b>Bold text</b>"]
html_data = pd.DataFrame(texts, columns=['HTML'])
html_data
html_data['HTML'].str.findall(pattern)
0 [<div>, <td valign='top'>, </td>, </div>]
1 [<a href='http://ds100.org'>, </a>]
2 [<b>, </b>]
Name: HTML, dtype: object
Practice: pandas regex#
Valid social security numbers follow the pattern XXX-XX-XXXX, where X is a digit. Write a function that takes the following, tranform into a dataframe, and returns a list of all valid social security numbers.
ssn = ['a82-ng-397d',
'393-572910-38',
'shhhhh',
'123-45-6789 bro or 321-45-6789',
'99-99-9999',
'703-28-6930']