pandas Part III#
This document introduces the joining of multiple datasets in pandas.
Basic idea of relational databases#
In many occasions data do not reside in one single table. Instead, they reside in multiple tables connected by identifiers, because of
storage efficiency: the same data do not have to be stored multiple times.
data consistency: multiple copies of data are prone to inconsistency.
standard access: all relational databases offer a similar way of accessing the data.
In CS 217, you will dive into the design of relational databases and the language to access them, Structured Query Language (SQL).
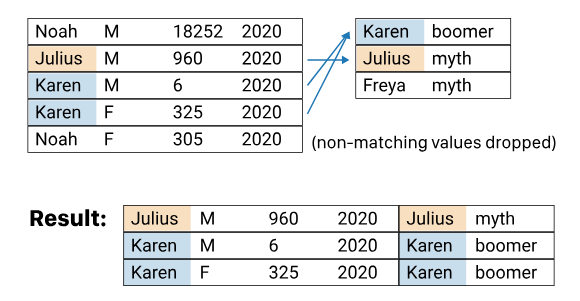
Coded example with baby names#
Tzioumis [2018] has studied how often various first names are used by people of certain racial and Hispanic origin groups.
The data contain the following information (columns):
import pandas as pd
baby = pd.read_csv('../data/ssa-names.csv.zip')
names_demo_meta = pd.read_excel('../data/firstnames.xlsx')
names_demo = pd.read_excel('../data/firstnames.xlsx', sheet_name='Data')
pd.set_option('display.max_colwidth', 80)
names_demo_meta
| Field | Description | |
|---|---|---|
| 0 | firstname | First name |
| 1 | obs | Number of occurrences in the combined mortgage datasets |
| 2 | pcthispanic | Percent Hispanic or Latino |
| 3 | pctwhite | Percent Non-Hispanic White |
| 4 | pctblack | Percent Non-Hispanic Black or African American |
| 5 | pctapi | Percent Non-Hispanic Asian or Native Hawaiian or Other Pacific Islander |
| 6 | pctaian | Percent Non-Hispanic American Indian or Alaska Native |
| 7 | pct2prace | Percent Non-Hispanic Two or More Races |
Are the most popular baby names used by people of a variety of ethnic groups?
# data cleanup for baby names
baby['Name'] = baby['Name'].str.lower()
# data cleanup for demographics info
names_demo['firstname'] = names_demo['firstname'].str.lower()
# reorganize data
most_occrrence_names = baby.loc[baby.groupby(['Year', 'Sex'])['Count'].idxmax()]
most_occrrence_names
| State | Sex | Year | Name | Count | |
|---|---|---|---|---|---|
| 4917850 | PA | F | 1910 | mary | 2913 |
| 5036503 | PA | M | 1910 | john | 1326 |
| 4918257 | PA | F | 1911 | mary | 3188 |
| 5036756 | PA | M | 1911 | john | 1672 |
| 4918688 | PA | F | 1912 | mary | 4106 |
| ... | ... | ... | ... | ... | ... |
| 6302995 | CA | M | 2019 | noah | 2677 |
| 6139273 | CA | F | 2020 | olivia | 2350 |
| 6305858 | CA | M | 2020 | noah | 2625 |
| 6142887 | CA | F | 2021 | olivia | 2395 |
| 6308651 | CA | M | 2021 | noah | 2591 |
224 rows × 5 columns
# joining data tables
most_occrrence_names.merge(names_demo, # which two datasets to join
how='inner', # method of join
left_on='Name', # which column (key) to connect with in the first dataset
right_on='firstname') # which column (key) to connect with in the second dataset
| State | Sex | Year | Name | Count | firstname | obs | pcthispanic | pctwhite | pctblack | pctapi | pctaian | pct2prace | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | PA | F | 1910 | mary | 2913 | mary | 23598 | 2.509 | 92.351 | 3.327 | 1.526 | 0.174 | 0.114 |
| 1 | PA | M | 1910 | john | 1326 | john | 51696 | 1.729 | 94.384 | 1.729 | 1.932 | 0.124 | 0.101 |
| 2 | PA | F | 1911 | mary | 3188 | mary | 23598 | 2.509 | 92.351 | 3.327 | 1.526 | 0.174 | 0.114 |
| 3 | PA | M | 1911 | john | 1672 | john | 51696 | 1.729 | 94.384 | 1.729 | 1.932 | 0.124 | 0.101 |
| 4 | PA | F | 1912 | mary | 4106 | mary | 23598 | 2.509 | 92.351 | 3.327 | 1.526 | 0.174 | 0.114 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 219 | CA | M | 2019 | noah | 2677 | noah | 264 | 1.515 | 92.045 | 2.273 | 3.409 | 0.379 | 0.379 |
| 220 | CA | F | 2020 | olivia | 2350 | olivia | 449 | 37.194 | 47.661 | 6.682 | 7.795 | 0.445 | 0.223 |
| 221 | CA | M | 2020 | noah | 2625 | noah | 264 | 1.515 | 92.045 | 2.273 | 3.409 | 0.379 | 0.379 |
| 222 | CA | F | 2021 | olivia | 2395 | olivia | 449 | 37.194 | 47.661 | 6.682 | 7.795 | 0.445 | 0.223 |
| 223 | CA | M | 2021 | noah | 2591 | noah | 264 | 1.515 | 92.045 | 2.273 | 3.409 | 0.379 | 0.379 |
224 rows × 13 columns
Comparison to a query using SQL (CS 217)
SELECT *
FROM most_occurrence_names
INNER JOIN names_demo
ON most_occurrence_names.name = names_demo.firstname
A truncated example with healthcare data (MIMIC-III)#
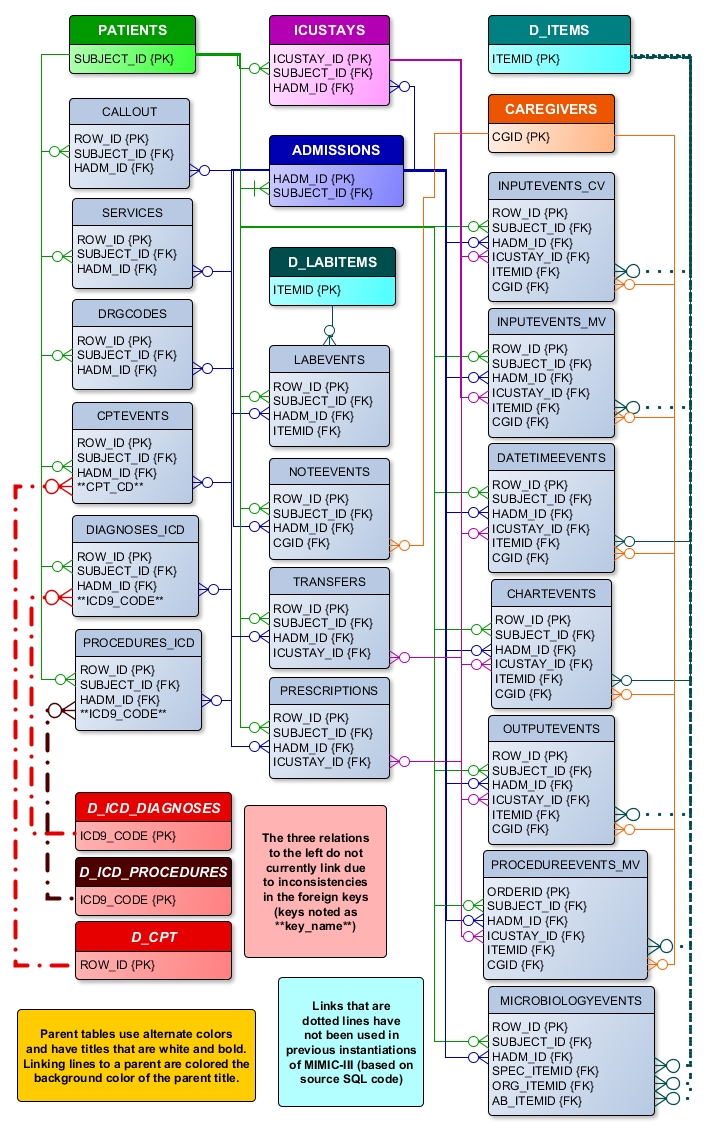
Fig. 3 Example of a relational database (MIMIC III)#
Practice: MIMIC-III#
Using the MIMIC-III demo dataset (PATIENTS.csv and ADMISSIONS.csv),
Create a table that includes all admissions with the corresponding patient information. (Think about which way to join/merge.)
Report the number of admissions for each patient.
Report the number of admissions grouped by gender and ethnicity.